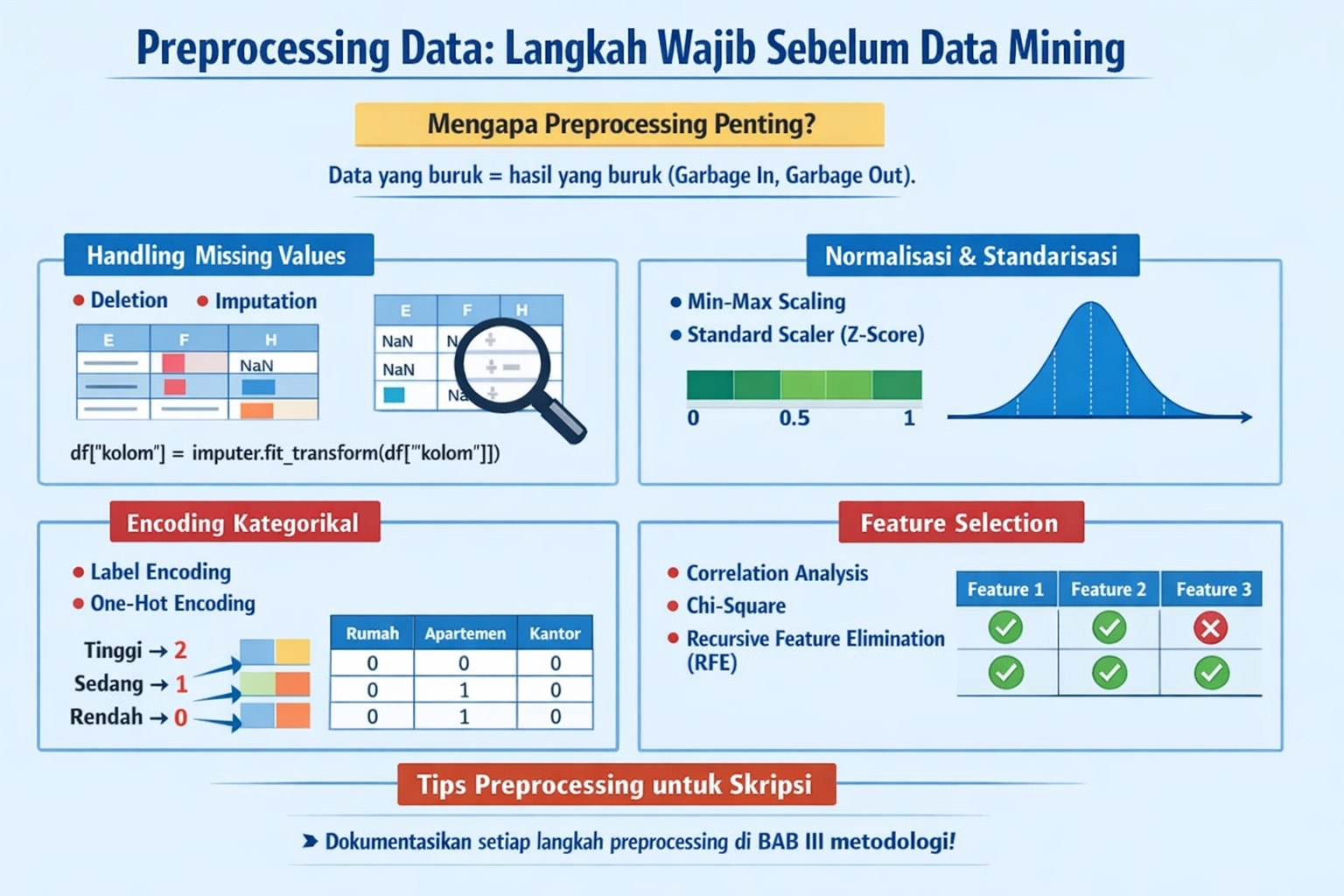
Mengapa Preprocessing Penting?
Data mentah jarang siap digunakan langsung. Preprocessing adalah tahap kritis untuk membersihkan dan menyiapkan data agar algoritma data mining dapat bekerja optimal. Data yang buruk = hasil yang buruk (Garbage In, Garbage Out).
1. Handling Missing Values
Data yang hilang harus ditangani sebelum pemodelan:
- Deletion: Hapus baris/kolom dengan missing value (jika jumlahnya sedikit).
- Imputation: Isi dengan mean, median, modus, atau nilai prediksi.
import pandas as pd from sklearn.impute import SimpleImputer # Cek missing value print(df.isnull().sum()) # Isi dengan mean untuk numerik imputer = SimpleImputer(strategy='mean') df['kolom'] = imputer.fit_transform(df[['kolom']])
2. Normalisasi dan Standarisasi
Menyamakan skala data agar tidak ada fitur yang mendominasi:
- Min-Max Scaling: Mengubah range data ke 0-1.
- Standard Scaler (Z-Score): Mean=0, Std=1.
from sklearn.preprocessing import MinMaxScaler, StandardScaler # Min-Max Scaling scaler = MinMaxScaler() X_normalized = scaler.fit_transform(X) # Standarisasi scaler = StandardScaler() X_standardized = scaler.fit_transform(X)
3. Encoding Kategorikal
Mengubah data kategorikal menjadi numerik:
- Label Encoding: Untuk ordinal (Rendah=0, Sedang=1, Tinggi=2).
- One-Hot Encoding: Untuk nominal (membuat kolom dummy).
4. Feature Selection
Memilih fitur yang paling relevan untuk model:
- Correlation Analysis: Hapus fitur yang berkorelasi tinggi.
- Information Gain / Chi-Square: Untuk klasifikasi.
- Recursive Feature Elimination (RFE): Otomatis memilih fitur terbaik.
Tips Preprocessing untuk Skripsi
Dokumentasikan setiap langkah preprocessing dengan baik di BAB III metodologi. Penguji sering bertanya tentang alasan pemilihan teknik preprocessing tertentu.


