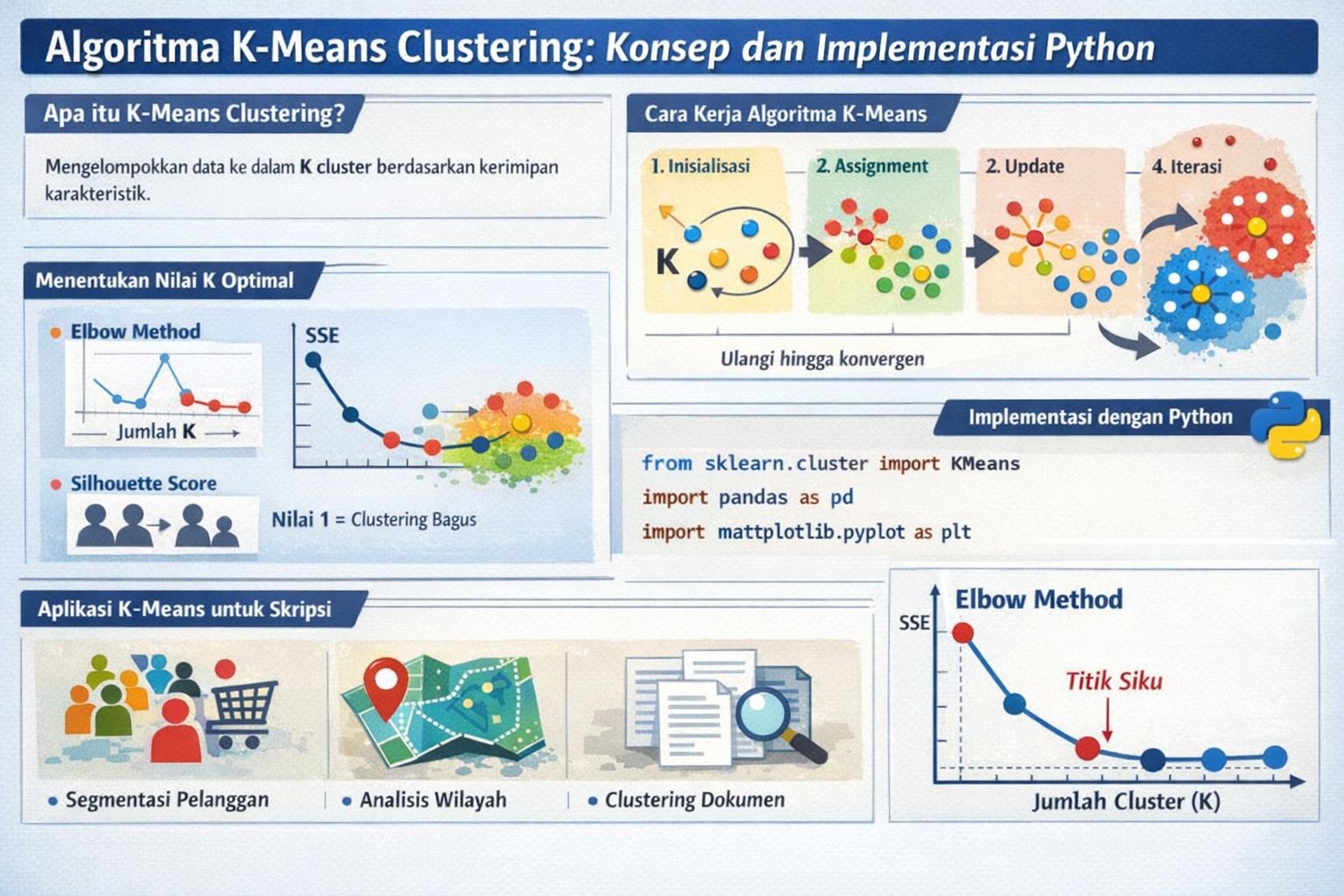
Apa itu K-Means Clustering?
K-Means adalah algoritma unsupervised learning yang mengelompokkan data ke dalam K cluster berdasarkan kemiripan karakteristik. Algoritma ini sangat populer karena sederhana namun efektif.
Cara Kerja Algoritma K-Means
- Inisialisasi: Tentukan jumlah cluster (K) dan pilih K centroid secara acak.
- Assignment: Hitung jarak setiap data ke semua centroid, assign ke cluster terdekat.
- Update: Hitung ulang centroid berdasarkan rata-rata anggota cluster.
- Iterasi: Ulangi langkah 2-3 hingga centroid tidak berubah (konvergen).
Menentukan Nilai K Optimal
1. Elbow Method
Plot nilai SSE (Sum of Squared Errors) terhadap jumlah K. Pilih K di titik "siku" dimana penurunan SSE mulai melambat.
2. Silhouette Score
Mengukur seberapa baik setiap data cocok dengan clusternya. Nilai mendekati 1 = clustering bagus.
Implementasi dengan Python
from sklearn.cluster import KMeans from sklearn.preprocessing import StandardScaler import pandas as pd import matplotlib.pyplot as plt # Load dan preprocessing data data = pd.read_csv('data_pelanggan.csv') X = data[['usia', 'pendapatan', 'skor_belanja']].values scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # Elbow Method sse = [] for k in range(1, 11): kmeans = KMeans(n_clusters=k, random_state=42) kmeans.fit(X_scaled) sse.append(kmeans.inertia_) plt.plot(range(1, 11), sse, marker='o') plt.xlabel('Jumlah Cluster (K)') plt.ylabel('SSE') plt.title('Elbow Method') plt.show() # Model final dengan K optimal kmeans = KMeans(n_clusters=3, random_state=42) data['cluster'] = kmeans.fit_predict(X_scaled) print(data.groupby('cluster').mean())
Aplikasi K-Means untuk Skripsi
- Segmentasi pelanggan berdasarkan perilaku belanja.
- Pengelompokan wilayah berdasarkan indikator sosial ekonomi.
- Clustering dokumen atau berita berdasarkan topik.


